
I Introduction
Après l’analyse lexicale qui vérifie que chaque « mot/valeur » utilisé soit correct il faut maintenant aborder l’analyse syntaxique qui va principalement vérifier que la « grammaire » corresponde à ce que l’on attend.
La « grammaire » va ainsi définir la combinaison des mots à respecter. Par Exemple un « IF » doit être suivi d’une condition puis d’un « THEN » : IF (condition) THEN.
L’analyse syntaxique permet également de faire d’autres opérations. Pour résumer ces opérations seront les suivantes :
- vérifier que la grammaire soit correcte ;
- traduire le programme sous forme d’un arbre. Ce qui permettra par la suite de transformer cet arbre en code ou opérations ;
- produire du code intermédiaire.
II Grammaire
II.1 différents type de grammaires …
En informatique, il est souvent fait mention de la hiérarchie de Chomsky qui classifie les langages formels en plusieurs classifications.
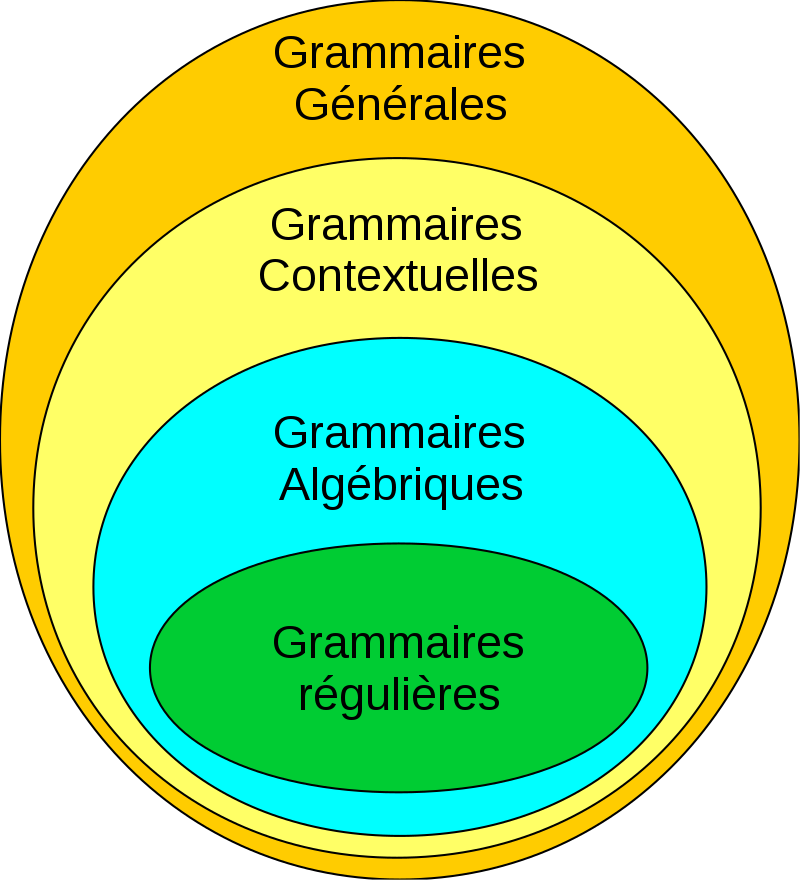
hiérarchie de Chomsky
Ces différentes grammaires sont les suivantes :
- de type 0 : grammaires générales
- de type 1 : grammaires contextuelles
- de type 2 : grammaires algébriques, généralement utilisées par des analyseurs syntaxiques
- de type 4 : grammaires régulières, domaine ou l’on utilise des expressions régulières. Souvent utilisé par des analyseurs lexicaux
Pour notre part nous allons donc nous concentrer sur la grammaire algébriques.
II.2 Grammaire algébrique…
II.2.1 Règles générales
La notion de grammaire formelle va être utilisée. Cette grammaire est constituée des 4 éléments :
- un ensemble de symboles dit terminaux ;
- un ensemble de symbole dit non terminaux ;
- un élément de l’ensemble des non terminaux, appelé axiome et souvent noté S ;
- un ensemble de règles de production composé d’un non terminal, de suite de terminaux et de non terminaux ;
II.2.2 Un peu d’explications
Un élément terminal peut être un chiffre, une lettre ou un opérateur (+, -, =). Lorsque on attend aucun élément (une chaîne vide), il est souvent utilisé le symbole Є
Un élément non terminal est composé d’éléments terminaux. Par exemple un nombre (élément non terminal) et composé de plusieurs chiffres (éléments terminaux).
Une règle de production est une règle d’écriture qui permet de définir toutes les chaines correctes.
Exemple :
| Règle de grammaire | Commentaire |
| S -> lettreS | Règle de production S composé d’éléments non terminaux (lettre) et d’une règle de production |
| S-> lettre | Є | Règle de production composé d’un élément non terminal (lettre) ou d’un élément terminal ( Є ) |
| lettre -> a|b | Une lettre est un élément nom terminal qui peut être composé d’éléments terminaux (soit un « a » ou un « b ») |
Ainsi les exemples ci-dessous sont acceptés par la grammaire ci-dessus :
- « a », « aa », « aaa », …
- « b », « bb », »bbb », …
- « ba », « ab », « aaaaab », …
Autre exemple :
Soit la grammaire pour définir une opération prenant en compte la multiplication et l’addition de variables
E → E + T | T
T → T × F | F
F → ( E ) | id
E, T et F sont des non terminaux. +, ×, (,) et id sont des terminaux.
Le symbole » | » indique « ou ». Exemple : E → A | B . Ainsi E peut être A ou B.
Nous allons voir si id + id est correct ?
| étape | Opération : id + id | Grammaire : E → E + T | T T → T × F | F F → ( E ) | id |
| 1 | id | F → ( E ) | id |
| 2 | id + | correspond à E → E + T mais la règle F → ( E ) impose que E soit entre parenthèses donc –> erreur ou ne correspond pas à la grammaire |
Nous allons voir si (id*id) est correct ?
| étape | (id*id) | E → E + T | T T → T × F | F F → ( E ) | id |
| 1 | ( | F → ( E ) | id |
| 2 | (id | F → ( E ) | id E → E + T | T T → T × F | F F → ( E ) | id |
| 3 | (id* | F → ( E ) | id E → E + T | T T → T × F | F |
| 4 | (id*id | F → ( E ) | id E → E + T | T T → T × F | F F → ( E ) | id |
| 5 | (id*id) | F → ( E ) | id E → E + T | T T → T × F | F F → ( E ) | id |
Toutes les conditions ont été satisfaites … (id*id) correspond à la grammaire attendue.
II.2.3 Méthodes d’analyse syntaxique
La plupart des méthodes d’analyses sont classées en 2 catégories :
- les méthodes d’analyse descendantes (top-down parsing). Méthodes les plus simples car elles sont facilement utilisables à la main,
- les méthodes d’analyse ascendantes (bottom-up parsing). Méthodes les plus performantes, notamment utilisées par l’analyseur yacc.
Ici nous allons nous concentrer sur les méthodes d’analyses descendantes.
Le type d’analyse descendante porte les noms suivant :
- LL (pour Left to right, Leftmost derivation en anglais). Cet analyseur lit de gauche à droite et produit une dérivation à gauche. L’analyse se fait en une seule passe sur le mot d’entrée. Ce type d’analyse est aussi appelé LL(k) lorsque elle utilise une fenêtre de k lexèmes.
Exemple de type d’analyse ascendante :
- LR (pour Left to right, Rightmost derivation en anglais). Cet analyseur lit de gauche à droite et produit une dérivation à droite. On parle également d’analyseur de type LR(k) où k représente le nombre de symbole non consommé.
- SLR ou LR simple.
- LLAR (Look-Ahead Left-to-right Rightmost derivation) qui est une amélioration du type LR.
Pour ces analyseurs, n’importe quelle grammaire n’est pas applicable. Elle doit être de type « non ambiguë » et avoir certaines spécifiés comme la factorisation à gauche par exemple. Un analyseur descendant et déterministe est dit prédictif.
analyse par descente récursive
analyse prédictive par descente non-recursive
Pour aller plus loin :
- https://fr.wikipedia.org/wiki/Grammaire_formelle
- https://fr.wikipedia.org/wiki/Symboles_terminaux_et_non_terminaux
- https://henri-garreta.developpez.com/tutoriels/techniques-outils-compilation/?page=page_3#LIII-A-1